I’m back, and the fifth week of Google Summer of Code has just ended. I have missed 10 days, which means I haven’t done anything on week #4 :(. This is what I managed to do on the second half of this week:
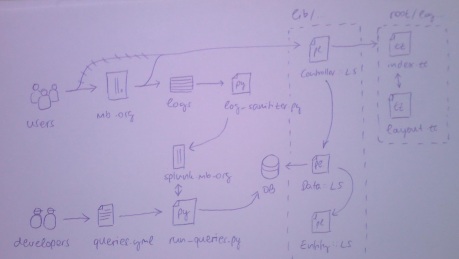
There were some discussions about the way logs are sanitized. Oliver (ocharles) suggested that we parse URL parameters, and try to match an e-mail regex on each value. I modified the script so it finds log entries that would be anonimized if we did things this way, and mailed the results to Robert. Unfortunately 99.9% of entries are real data, that would be lost.
On the other hand I found another type of log entry that contains sensitive information, and wasn’t filtered by regexes. I wrote a new regex that will match these entries, and I’ll push the new code to the repository before we start sanitizing logs on a daily basis.
This week’s most important task was to come up with a schema that we store query results in. Ian (ianmcorvidae) suggested that we store query results in JSON format, which is a very good idea. Basically we will have two types of queries: queries that we want to keep a historical record of, and queries for which we are only interested in the latest results. For example keeping the historical record for top artists is a good idea, but for other queries it might be a waste of space. This is the schema we have came up with so far:
CREATE TABLE log_statistic
(
id SERIAL,
timestamp TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
report_type VARCHAR(100) NOT NULL,
data TEXT NOT NULL -- JSON data
);
This allows many more report types in the future, so if we want to handle queries differently we can just do that. It is important, that the timestamp is kept for each row.
I installed the MusicBrainz server VM on my computer to experiment with the database. I added the table described above to the database. I had to install the psycopg2 module for python to access the PostgreSQL database. The last step for this week would have been to run queries on splunk.musicbrainz.org, and store the results in the database. Unfortunately I was not able to connect to our Splunk server from a distance. This shouldn’t be that difficult, so it will soon be done. For now I’ve ran the queries on my own local Splunk server for testing.
In the meantime, I wrote the python script that runs queries, and outputs the results in JSON format. Right now the queries are stored in a csv file. Each row contains a query name and the query itself. Later more metadata will be added to this file, for example, how often does the query need to run.
The only thing left is to connect to the Splunk server and store the results in the VM’s database. This shouldn’t take long once I know which port/credentials to use.
Next week we will focus on indexing data and running queries periodically. After that I should get the popularity statistics working, and find a way to present the results on the website. I should also ask for a sandbox from Ian, so the results are visible online.